オーディオペア完全解説
こんにちは、うえしゅうです。
今回は最近流行っているオーディオペアについての情報をまとめていこうと思います。
自分自身も3月初め頃にオーディオペアに変えて3ヶ月ほど経ち、他のBLDerも続々と始めて知見が溜まってきたのでそれらをまとめていきます。
オーディオペアとは?
まずオーディオペアとは、「音素」をナンバリングして2つの音素のペアから1つの音を生成することで音記憶をしやすくする手法です。 音素とは音を構成する最小単位のことであり、日本語であればa,i,u,e,oの母音やk,s,t,nのような子音がそれに当てはまります。 これらをナンバリングすることで例えば[k,a]ならka(か)、[a,k]ならak(あく)といったように音が生成されます。
オーディオペアは元々英語圏で一般的に使われていたもので、僕たち日本のBLDerはそれを日本語に当てはめて使っています。
比較のために英語と日本語それぞれのオーディオペアについて軽く解説します。
英語のオーディオペア
まず、英語はアルファベット1つ1つに日本語で言う子音や母音(いわゆる音素のようなもの)のみが割り当てられているため、アルファベットの羅列を覚えようと思った場合は一種の変換が必要になります。 例えば[a,b,c,d]の4文字を覚えるときにそのままエービーシーディーと発音したら非効率ですよね。 なのでab, cadといったようにアルファベットを2文字以上くっつけないとそもそも音になりません。 そして子音と子音をくっつけようとすると間に母音が入らないと発音できないため上記の例では[c,d]がcadと変換されます。
この変換が英語のオーディオペアそのものです 英語圏の方々はアルファベットを覚えるときに自然とこの考えにたどり着くと思われます。
日本語のオーディオペア
日本語の場合、ひらがな1文字はすべて1つの音として成立しています。 そのためひらがなをナンバリングしても、ひらがなの羅列を覚えるのに変換は特に必要ありません。 これはこれで楽なのですが、日本語をもうちょっと詳しく見てみましょう。
ひらがな1文字は子音と母音、もしくは母音のみで構成されています。 例えば「か」は[k,a]と分解できます。
ここで、もし日本語を構成する子音と母音をナンバリングしたら「子音+母音」のペアをひらがな1文字と覚えることができ実質的な記憶量が1文字削減できる、という考えが浮かびます。 ひらがなナンバリングであれば2文字はどう頑張ってもひらがな2文字ですが、子音と母音のナンバリングであればたとえば[k,a]は「か」とひらがな1文字で済むのです。
これが日本語のオーディオペアの元となる考えになります。
ここから先は日本語のオーディオペアに絞って解説をしていきます。
メリットとデメリット
日本語オーディオペアのメリットとデメリットを解説します。
メリット
子音+母音はひらがな1文字になる
これが最大のメリットです。
ひらがなは濁音や半濁音も含めると約100音あり、エッジ440手順中約1/5がひらがな1文字と対応することになります。 例えばエッジ12文字で一回でもひらがな1文字の手順が出てくる確率は1-((440-100)/440)^6=0.78710…となり、約8割の確率で1文字以上の削減ができます。 これは裏を返せば削減できた文字の分だけ音記憶の量を増やせるということでもあります。 自分はもともとひらがなナンバリングのときは8文字しか音記憶できませんでしたが、オーディオペアに変えてから10文字の音記憶が余裕で可能になりました。
つまりオーディオペアの真のメリットは「音記憶の量を増やせる」です。
デメリット
2文字分析しないと音が断定できない
オーディオペアは音素ナンバリングのため、ひらがなナンバリングと違って2文字分分析しないと音が確定しません。 そのため分析の感覚が少し変わります。
オーディオペアの規則に慣れないといけない
オーディオペアは音素のペアからなる音ですが、両方子音の場合間に入る母音はa,i,u,e,oのどれでもできます。 この母音は準備段階で決めておいたほうが分析時に悩まなくて済みます。 裏を返すと分析時に分析した文字だけではなくその2文字に対応する間の母音まで思い出す必要があり、ナンバリング以外の知識も必要という部分が少し慣れがいる部分だと思います。
またオーディオペアには似た音を区別するために例外規則を設ける必要があり、これも知識として覚えておかないと分析ができないのが難しいところです。
日本語オーディオペア作成手順
ここからは日本語オーディオペアを始めるための準備を解説します。
使う音素の選定
まず日本語に存在する音素を列挙してみましょう
- 母音: a,i,u,e,o (あいうえお)
- 子音(濁りなし): k,s,t,n,h,m,y,r,w (かさたなはまやらわ)
- 子音(濁りあり): g,z,d,b,p (がざだばぱ)
- その他: sh,j,ch,ts,f,v (しじちつふぁゔぁ)
- 拗音: ky,gy,ny,hy,by,py,my,ry (きゃぎゃにゃひゃびゃぴゃみゃりゃ)
これらのうち、拗音は母音のa,u,oにしかくっつけられずiとeにはくっつけられません。(例: きゃきゅきょ) そのため基本的には拗音はナンバリングに含めません。
拗音を除いた日本語の音素は全部で25個です。 ここから23個の音素を選定していきます。 3BLDだけであればバッファの裏側ステッカーはいらないため22個で済みますが、多分割BLDのセンターやウイングエッジの場合は23個必要のためここでは23個の音素を選定します。
選定は好みで決めていいと思います。 僕の場合はv(ゔぁ)とts(つ)が使いにくそうと思ったので除外して23個にしました。
tsa, tsi, tsu, tse, tso(つぁつぃつつぇつぉ)って発音しづらくないですか? あとvも日本語に出てきにくい音だったので除外しました。
オーディオペア表を埋める
使う音素が決まったらオーディオペア表を作りましょう。
子音+母音はひらがな1文字([k,a]→ka)、母音+子音は普通につなげて発音([a,k]→ak)、母音+母音も普通につなげて発音([a,u]→au)、子音+子音は間に適当な母音を入れる([k,g]→kag)、と作っていきます。
ちなみに自分が使っているオーディオペアの表をスプレッドシートで公開しているので参考にしてみてください。
ここで、オーディオペア表の作成についていくつかポイントを説明します。
1. 混同しそうな2文字ペアは間の母音を変えて区別
例えば[h,m]→hamと[h,n]→hanが音が似通ってて区別しづらいなーと思ったとします。
そういうときは間の母音を変えてみましょう。
例えば[h,m]をhomという音にすればhanと区別がしやすくなるかと思います。
2. 間に母音を入れたときに実在の単語になるとベター(諸説あり)
例えば[d,g]をdagとするよりもdog(犬)とする方が音に親近感がありませんか? なるべく自分の知ってる単語に寄せたほうが知ってる音として認識しやすいのではないか、というのが僕の意見です。
3. 間の母音はバラエティに富んでいた方が覚えやすそう(諸説あり)
例えば間の母音をすべてaにしていたとします。 そうすると[k,g,s,z,t,p,h,b]はkag saz tap hab(かぐさずたぷはぶ)となりますね。
でもこの文字列って母音的に「アウ」の音が連続していて混同してきませんか?僕はしました。
そこで、[k,g,s,z,t,p,h,b]をkog saz tip hab(こぐさずてぃぷはぶ)と変換してみましょう。 それぞれの音が子音だけでなく母音でも区別することができ、混同がしにくくなったように思います。(僕だけ?)
という感じで、なるべくいろんな母音を振っていったほうが音の混同を防ぎやすいかなと僕は思います。
4. 例外規則について
オーディオペア表を埋めていくとわかりますが、この2文字どう発音するんだろう?と悩む2文字ペアはいくつかあります。 自分の場合は2文字目にhもしくはrが来たときの発音で悩みました。
例えば[k,h]をkah(かー)という音にしようとすると[k,a]のka(か)と被ってしまいます。 また[k,r]をkar(かー)にしたときもやはり同じく被ります。
この問題について、僕はhが2文字目に来たときはuiに変換、rが2文字目に来たときはoiに変換、とするダブルナンバリング方式で解決しました。 この方法を使うと[k,h]→kui、[k,r]→koi、となり[k,a]→kaと被らなくなります。
また、どうしても確実に被ってしまう2文字ペアはいくつか存在します。 例としては以下が挙げられます。
- ziとji
- huとfu
- siとshi
- auとaw
- aiとay
これらの解決策として、まず上の3つはどちらかの末尾にnをつけることで解決しました。
- [z,i]→zin、[j,i]→ji
- [h,u]→hun、[f,u]→fu
- [s,i]→sin、[sh,i]→shi
zinは[z,n]と被りそうと思うかもしれませんが、[z,n]をzanとしておけばこれらは母音で区別ができます。
そしてauとaw、aiとayについては、1文字目に母音が来て2文字目にwかyが来たときは先頭にkyをつけることにしました。
- [a,u]→au、[a,w]→kyaw(きゃう)
- [a,i]→ai、[a,y]→kyay(きゃい)
これらは僕が使っている例外規則ですが、自分で考案した他の例外規則を使用しても全然問題ありません。 大切なのは、オーディオペアには性質上どうしても区別がつかない音が存在するため何かしらの例外規則が必要だということです。
みなさんも色々考えて自分なりの例外規則を作ってみてください。
ナンバリング案
オーディオペア表が完成したところで、実際にエッジにナンバリングしていきましょう。 ここでは自分が考えたナンバリング案をいくつか紹介します。
1. 自分の現ナンバリング
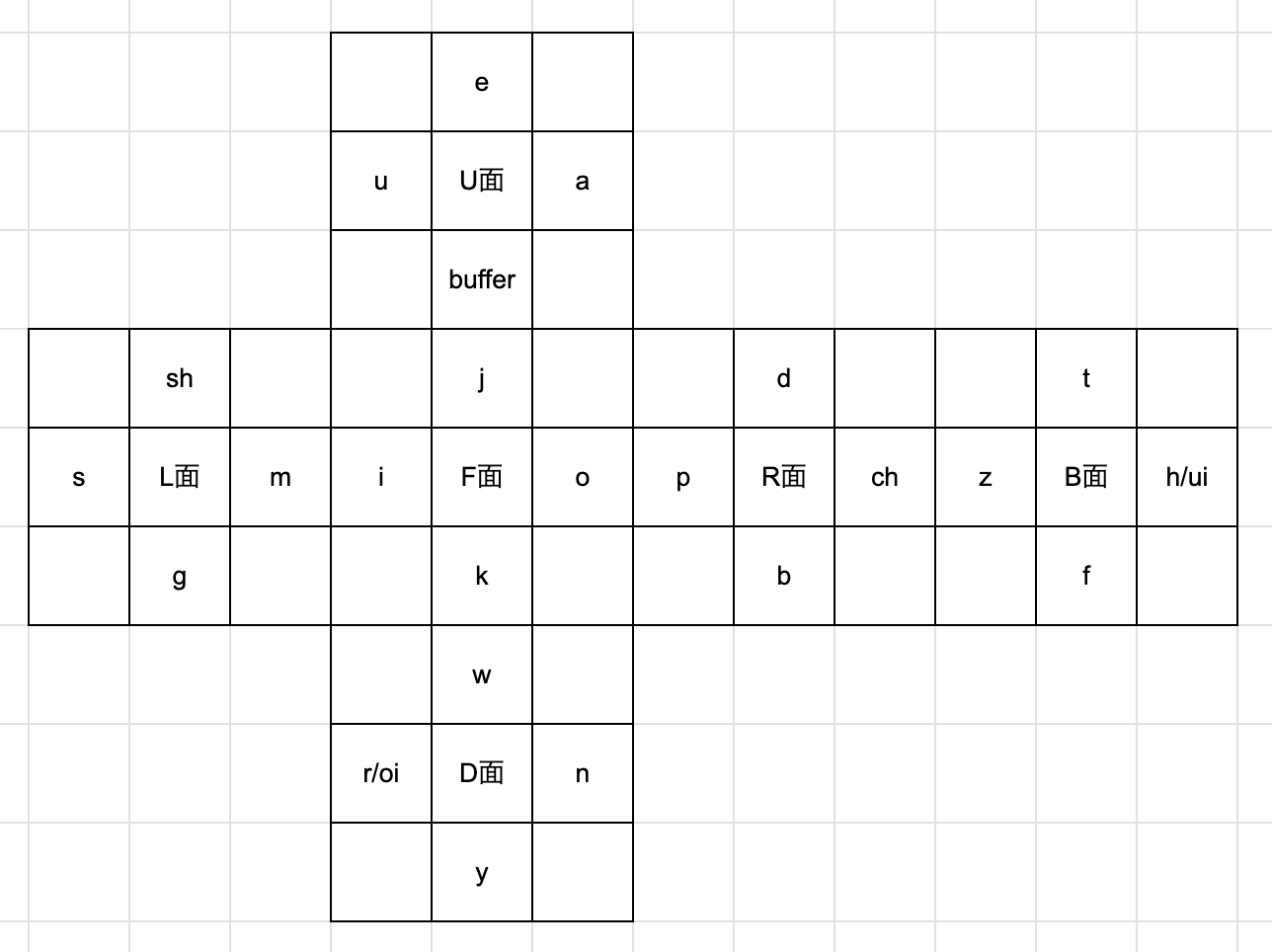
このナンバリングは僕が前に使っていた旧Cube Voyageナンバリングに寄せて作っています。
詳しく言うと、あ→a、い→i、う→u、え→e、お→o、か→k、こ→g、さ→s、し→sh、そ→z、た→t、ち→ch、と→d、な→n、という変換がなされています。 それ以外の音素は割と適当に振っていますが、一応余った音素をUFLBRD面の順番にひらがな順に振っていったつもりです。
元々ひらがなナンバリングを使っていた人はステッカーの色と文字が頭の中ですでに固く結びついてしまっている人が多いので、先程の対応表をもとに前のナンバリングに近い音素ナンバリングにすると慣れが早いかもしれません。
2. 音素を行ごとでグループ化して面ごとに振るナンバリング
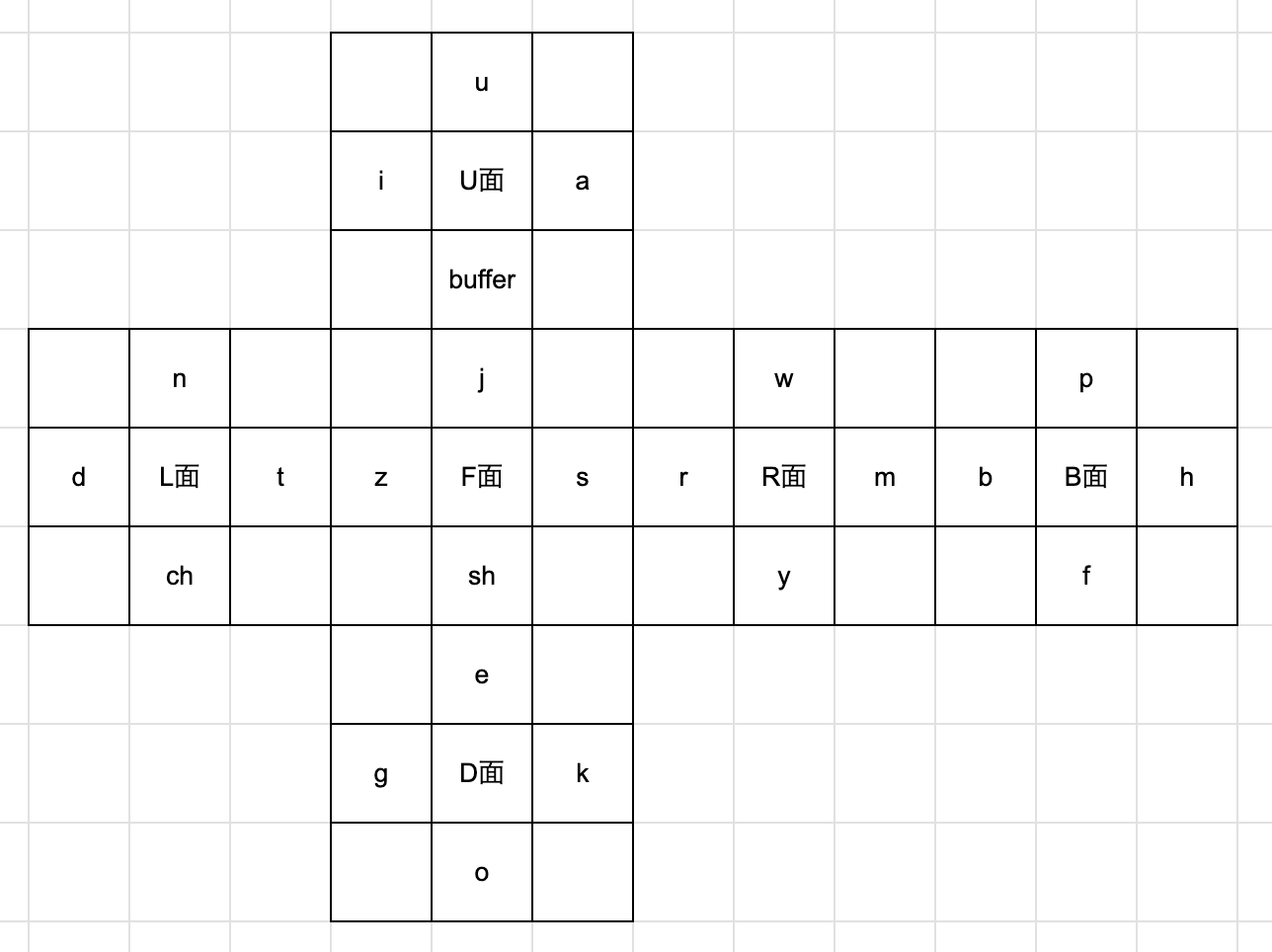
このナンバリングはU面が母音のa,i,u、D面が母音のe,oとか行系のk,g、F面がさ行系のs,sh,z,j、L面がた行系のt,ch,dとな行のn、B面がは行系のh,f,b,p、R面がその他のm,y,r,wという風に、行ごとにグルーピング化してそれぞれを面にまとめています。
面ごとに行がまとまっているのでナンバリングにも慣れやすいと思います。
NR holderのまっくんが確か前にこの方式のナンバリングを使っていましたね。(今は違うらしい)
3. 母音を1パーツにまとめるナンバリング
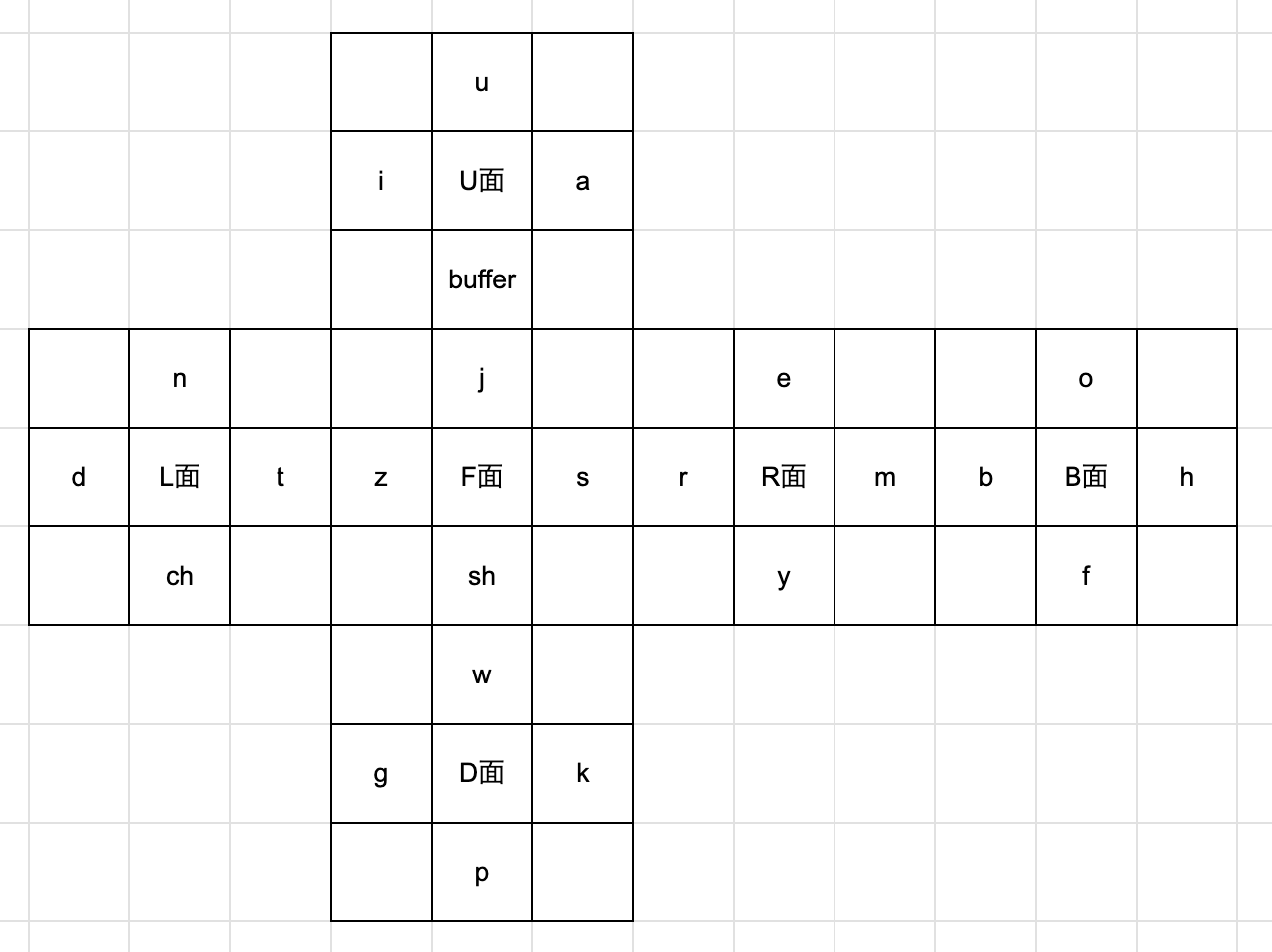
先程紹介した2つのナンバリング案はどちらも母音が別のエッジパーツにあるナンバリングでしたね。
今回のナンバリングは母音がURとRU、UBとBUにあり1パーツにまとまっています。
これの何がいいかというと、URもしくはUBを分析した場合必ず母音が文字列に出現するということです。 母音が出現してそれが2文字目に来れば基本的にはひらがな1文字になるためお得ですよね。 最初にも話した通り、日本語オーディオペアの最大のメリットは子音+母音がひらがな1文字になることなので、ひらがな1文字がなるべく出やすいナンバリングにできればメリットを有効活用できます。
ここで一つ統計情報を。
みんな予想してた通り、
— けいていぃ゛ (@keit_cube) May 3, 2023
母音を同パーツに配置した方が
・1モーラの音が全くでないソルブが少ない
・1ソルブで1モーラが1~3回でやすい
逆に母音を離すと、
1ソルブで1モーラが4~5回でる可能性が高くなる
100回じゃ少ないのでもうちょい試行回数ほしいな
つまり母音を1パーツにまとめるこのナンバリングを使えば他のナンバリングよりもひらがな1文字が1回以上出現する確率が高いということです。
ただし、ひらがな1文字が4回以上出る確率は他のと比べて低いようです。 安定を取るか賭けを取るか、ということですね。
4. 子音と母音のダブルナンバリング
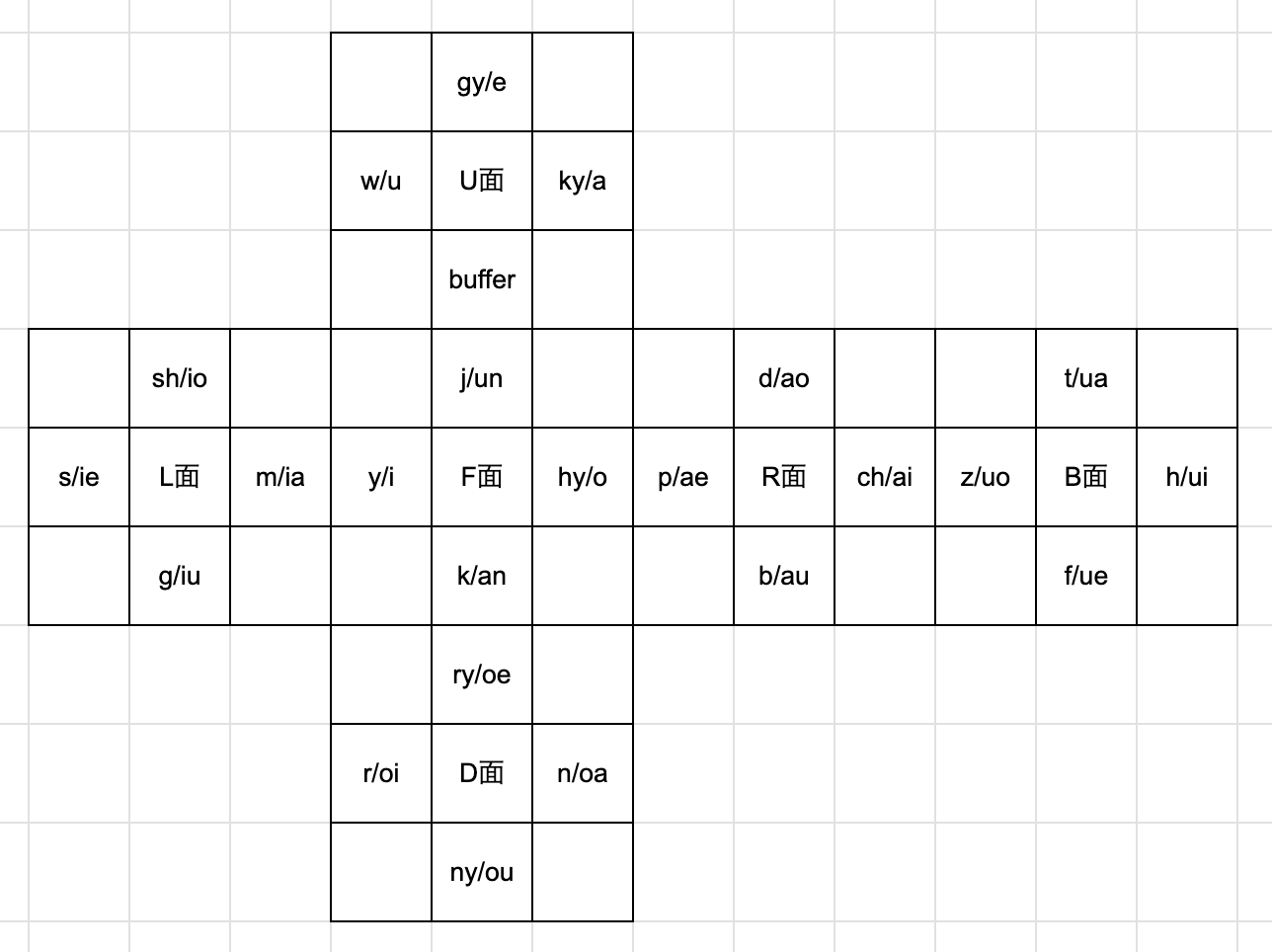
最後に変わったナンバリングを紹介します。
このナンバリングは1ステッカーにつき子音と母音をそれぞれナンバリングし、1文字目なら子音を、2文字目なら母音を使うといったものです。 日本語には母音は5個しかないですが、実は二重母音というものがあるらしく、uiやoiといった母音の連続は一つの母音と捉えることもできるそうです。
そして最初に音素から排除した拗音を子音として使い、母音として二重母音も許容することで子音と母音のダブルナンバリングは一応理論上は可能です。
実はまっくんの現在のナンバリングもこの方式のナンバリングらしく、ちょうど今慣らしている途中だそうです。
— K.H.Cuber (@Ma29K) May 27, 2023
このナンバリングから生成される音は確かに覚えやすい音になりそうな気はしますが、分析で頭パンクしそうでちょっと手は出しづらいですね。
おわりに
この記事では、自分が知っている日本語オーディオペアの情報をすべてまとめてみました。 日本語オーディオペアはまだ発展途上なのでより良い方法が編み出されるかもしれませんが、それもそれで楽しみですね。
最後にまとめると、日本語オーディオペアは「2音素がひらがな1文字になって実質的な文字数が減る可能性があり、その分音記憶の量が増やせる」のが最大のメリットです。
この記事がこれから日本語オーディオペアを始めるBLDerの助けになれば幸いです。
それでは。